The AI Rocket Ship
intelligence.join(analytics, on=["smarts"], how="full outer")
Accelerating GenAI Development with Palantir Foundry

Collab
Introduction
Palantir Foundry provides a vertically integrated operating system for Generative AI that contrasts with the distributed primitive approach of cloud hyperscalers (AWS/Azure/GCP). While hyperscalers offer raw compute and isolated model APIs, Foundry abstracts the integration layer via the Ontology. This architecture allows engineering teams to focus on function development, logic orchestration, and evaluation pipelines rather than infrastructure plumbing (e.g., vector database synchronization, context window management, and stateful tool execution).
Overview
The barrier to entry for Generative AI is low. Any developer can grab an API key from OpenAI or deploy Llama 3 on Hugging Face. The real gap is between a quick demo and a production-grade enterprise application that is reliable, secure, and maintainable.
For Architects and CTOs, the decision usually falls into two camps:
-
Primitive Approach: Requires manual orchestration of Azure OpenAI, Pinecone (Vector DB), LangChain (Application Logic), and FastAPI (Tool Execution). Engineers are responsible for maintaining the “glue code” that synchronizes state between these disparate services.
-
Platform Approach: Unifies the Data Layer, Logic Layer, and Application Layer. The Ontology serves as both the semantic graph and the vector store, on top of which we can create operational applications and LLM orchestrations.
The primitive approach maximizes flexibility and is attractive to teams that want fine-grained control over every component. The trade-off is a significant “Integration Tax” in Time-to-Market and ongoing maintenance. Let’s see why, in many enterprise scenarios, Foundry ends up delivering faster and with less operational overhead.
The Ontology: Context is everything
The hardest part of GenAI isn’t the model; it’s the Business Context. To make an LLM smart, you need to feed it clean, structured data about your business—your specific customers, assets, and orders
In a typical Azure-based stack (e.g., Azure OpenAI + Databricks + Azure AI Search):
- You ingest data into tables or a data lake.
- You build Retrieval-Augmented Generation (RAG) pipelines:
- Chunk documents and data
- Create embeddings
- Store them in a vector index
- Write code to query the index and stitch results back into prompts
This works, but you now manage:
- Staleness: Indexes can lag behind source systems unless pipelines are carefully scheduled and monitored.
- Loss of structure: Rich relationships (e.g., Incident → Asset → Plant) are flattened into unstructured text; the LLM sees fragments, not a cohesive graph.
Foundry’s Ontology is a semantic layer that maps data to business objects (e.g., Incident, Asset, Plant) and their relationships. That live, governed data graph is directly consumable by AI workflows:
- LLMs can reason over objects and links, not just text chunks.
- Foundry can still use embeddings and retrieval under the hood, but you work at the level of business semantics rather than raw indices.
- Security markings and lineage are applied once and propagate consistently.
In practice, this often reduces the time spent on building and maintaining bespoke RAG infrastructure - from weeks of custom plumbing to days of Ontology modeling before you can build the first useful AI workflow.
AIP Logic: Visual Chains vs. Brittle Code
With a DIY Azure/AWS stack, you typically write Python/TypeScript code to:
- Manage prompts and conversation memory
- Define tools/functions and their schemas
- Orchestrate multi-step reasoning (ReAct, agents, etc.)
- Handle retries, timeouts, and logging Rely on libraries like LangChain or Semantic Kernel, which evolve quickly and require continuous maintenance to keep up with breaking changes and new features.
This approach is powerful and highly customizable, but it tends to produce “glue code” that is hard to debug and expensive to maintain over time.
Foundry’s AIP Logic:
- Provides a low-code, visual backend for GenAI workflows.
- Handles orchestration, retries, context window management, and tool invocation natively.
- Offers a visual debugger, so you can inspect each step of the chain instead of tracing through logs scattered across several services.
- Still allows you to insert custom code where needed; it reduces boilerplate rather than constraining functionality.
Cloud providers are introducing similar orchestration capabilities (e.g., Azure AI Studio, Prompt Flow, Bedrock Agents), but these still need to be integrated with your data platform, security model, and frontend framework. In Foundry, those elements live in one environment.
From Chatbots to Autonomous Agents
The industry is shifting from basic “Chat + RAG” interfaces to agentic workflows-systems where AI uses tools to perform multi-step tasks.
In a custom Azure stack, building an agent typically requires you to:
- Define tools (functions) as JSON schemas or decorators.
- Implement a loop that:
- Parses the LLM’s responses for tool calls
- Executes the corresponding function
- Feeds outputs back to the model
- Manage conversation and application state in external stores (e.g., Redis, SQL).
Palantir AIP Agent Studio simplifies this pattern:
Tools as Ontology Actions
Bind existing Ontology Actions (e.g., Create_WorkOrder, Reschedule_Shipment) as tools. Tool definitions and wiring are handled by the platform, so you don’t manually maintain schemas and function-calling conventions. Additionally you can create custom tools using Typescript and just plug it in the agent studio.
Application context awareness
Agents running inside a Workshop app can read application variables directly (e.g., the currentIncident the user is viewing).
From assistant to automation
The same agent can act:
- As an interactive assistant with strict guardrails, or
- As a background worker triggered by other systems (e.g., “auto-review alerts and create work orders above a confidence threshold”).
DIY stacks can implement similar capabilities, but they usually require multiple services and custom code to achieve what Agent Studio offers as a unified environment.
Iteration Velocity: The Feedback Loop
Success in GenAI depends on speed of improvement, not just speed to first release. Models will hallucinate, business rules will shift, and requirements will evolve.
In a AWS/Azure stack, evaluation is often ad-hoc:
- Logging is spread across CloudWatch, App Insights, or custom stores.
- Test sets are manually curated in CSVs or notebooks.
- LLM-as-a-judge, if used, is usually implemented via custom scripts.
- It can be difficult to see how a prompt change affects performance across hundreds or thousands of real-world examples.
Foundry’s AIP Evals builds evaluation into the platform:
- You run your logic or agents against real Object Sets (e.g., “all incidents from last quarter,” “all support tickets tagged ‘billing’”).
- You can use a stronger model (e.g., GPT‑4) as a judge to grade outputs (e.g., “Did the agent reference the correct policy?” “Is this remediation safe?”).
- End-user feedback from Workshop apps (thumbs up/down, comments) feeds back into eval datasets automatically.
- Before and after metrics are visible across versions, making it much easier to deploy changes with confidence.
Azure and AWS allow you to assemble similar evaluation pipelines, but doing so generally requires combining multiple tools and building custom evaluation frameworks. In Foundry, this capability is available as part of the core development lifecycle.
Governance & Security: Production by Default
Cloud IAM models (Azure AD, AWS IAM) are comprehensive but fragmented when applied across a multi-service GenAI architecture. You typically manage:
- Permissions on your data lake/warehouse
- ACLs on your vector index
- Access policies on your APIs and frontends
- Custom logic to ensure LLMs don’t access data users should not see
Any misalignment between these layers can lead to data leakage or slow security reviews.
Foundry’s model:
- Applies markings and permissions at the data level, which propagate automatically to derived datasets, indexes, models, and applications.
- Executes agents with the end user’s permissions, not as superusers, so they cannot retrieve or reason over data the user is not allowed to access.
- Provides built-in lineage and audit trails, making it easier to understand what data contributed to a given output and which users or processes triggered an action.
For organizations with stringent compliance and audit requirements, this integrated approach often shortens security review cycles compared to a fully custom stack.
Example Use Case: Incident Triage Agent
Typical tech stack:
- Data + Ontology: Foundry(Incident, Asset, WorkOrder obejcts).
- LLM + Logic: AIP Logic + AIP Agent Studio
- Frontend: Foundry Workshop app
Say you have the following Ontology objects already created and powering up existing operational workflows. Now you want to add a Agentic workflow that automates the creation of work order based on the incident’s description.
Ontology have 4 objects - Incident, Asset, Work Order, Maintenance Event
Incidents are linked to Assets and Work Orders and Assets ar linked to Maintenance events
There’s also an action associated with Work Order to create a new work order.
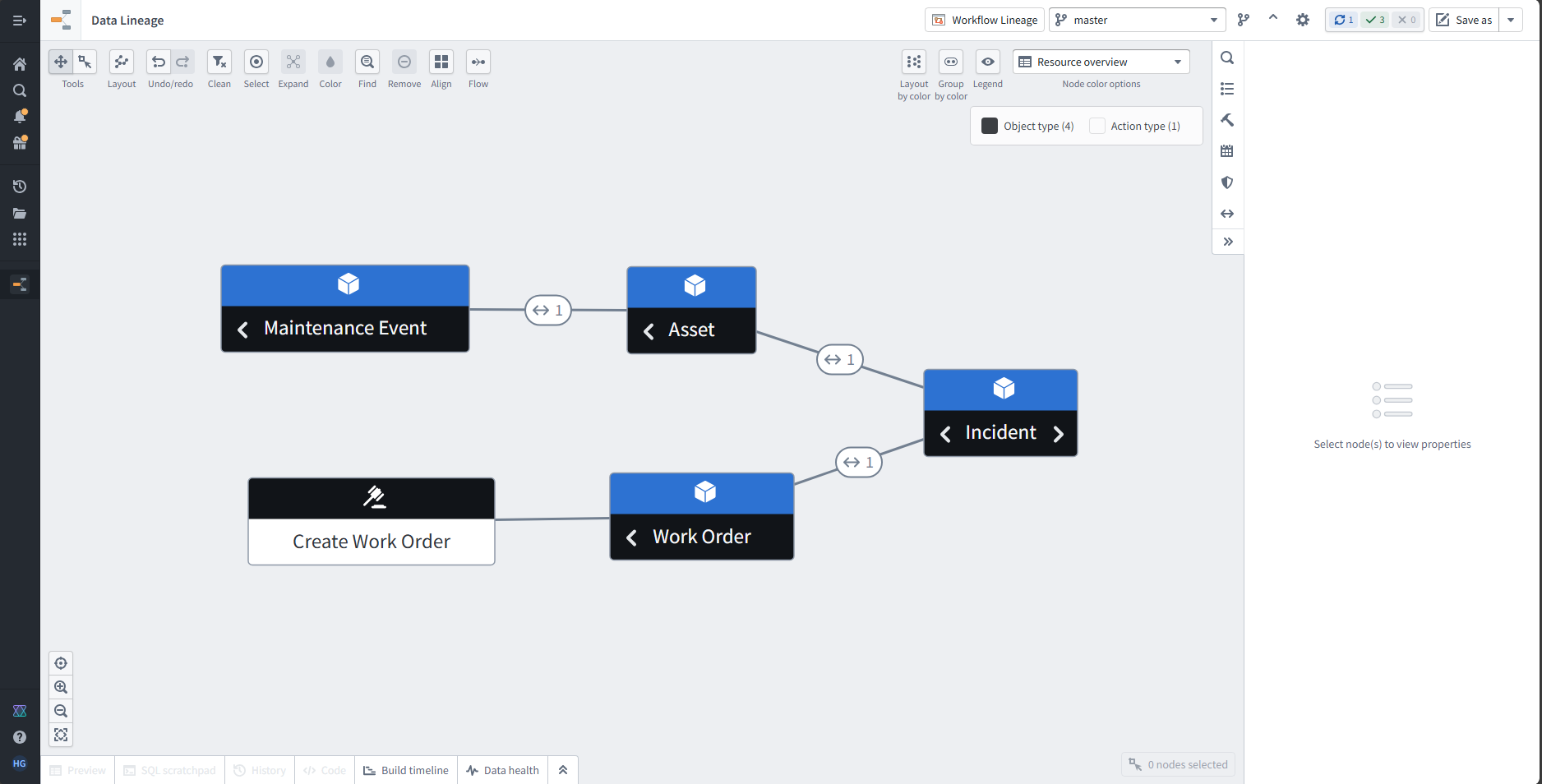
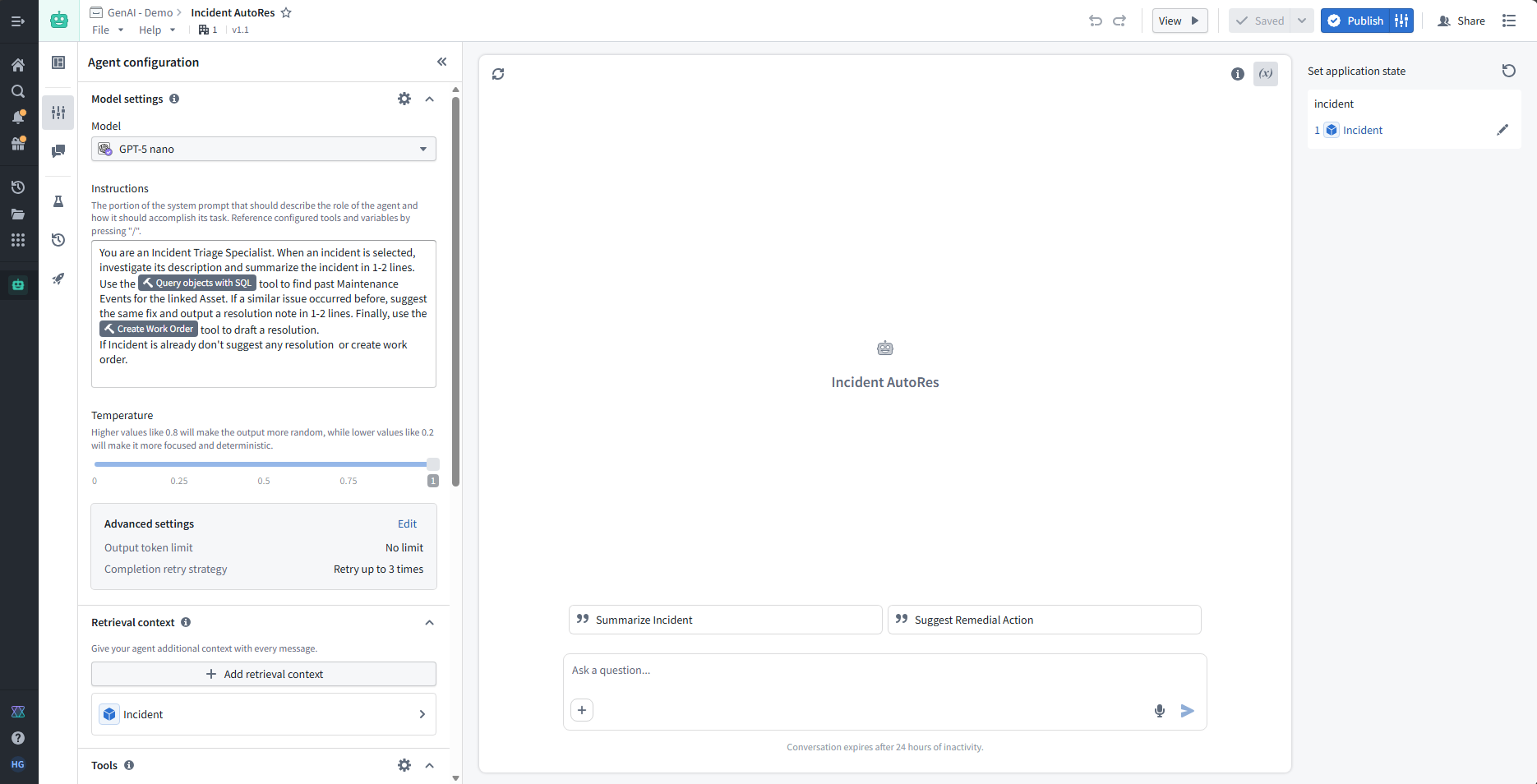
In Agent Studio, we can create agent that leverages the ontology objects and links bind the actions as tools and configure the agent via prompts and settings rather than raw JSON schemas.
We can select one of the LLM model available on foundry and give it below system prompt.
You are an Incident Triage Specialist. When an incident is selected, investigate its description and summarize the incident in 1-2 lines. Use the Query objects with SQL tool to find past Maintenance Events for the linked Asset. If a similar issue occurred before, suggest the same fix and output a resolution note in 1-2 lines.
Finally, use the Create Work Order tool to draft a resolution.
If Incident is already closed don't suggest any resolution or create work order.
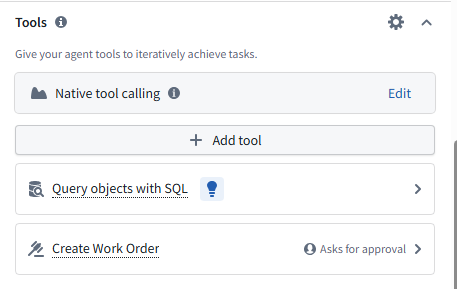
Setup the tools for LLM to use
- Action - this will allow LLM to trigger the create a work order action
- Query tool - this will allow LLM to traverse the ontology links to find similar historical incidents and work orders.
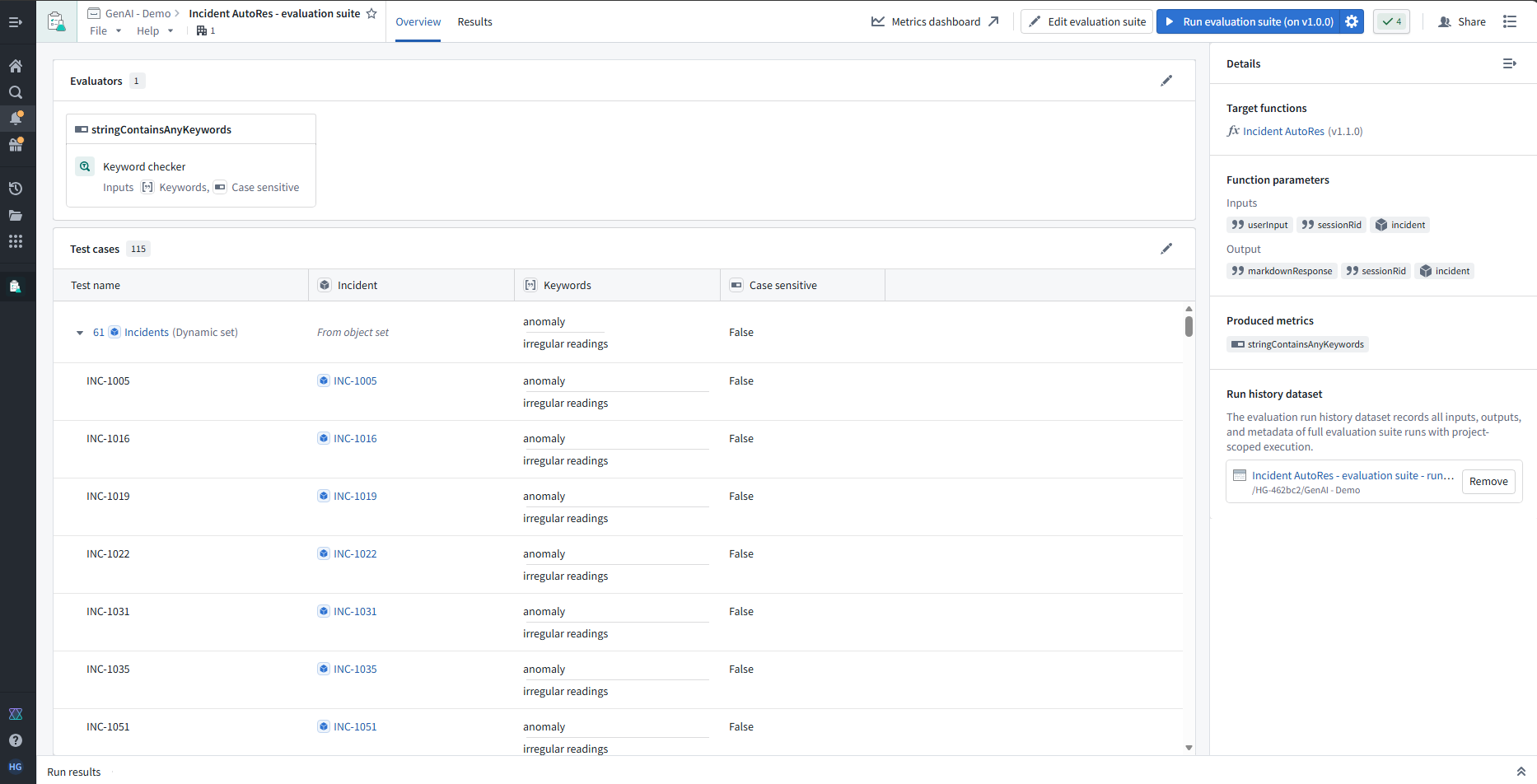
Set up AIP Eval, to test the agent on historical incidents,
Use keyword checker to check if LLM is identifying correct keywords and Use LLM-as-a-judge to score quality of generated summary and resolution text.
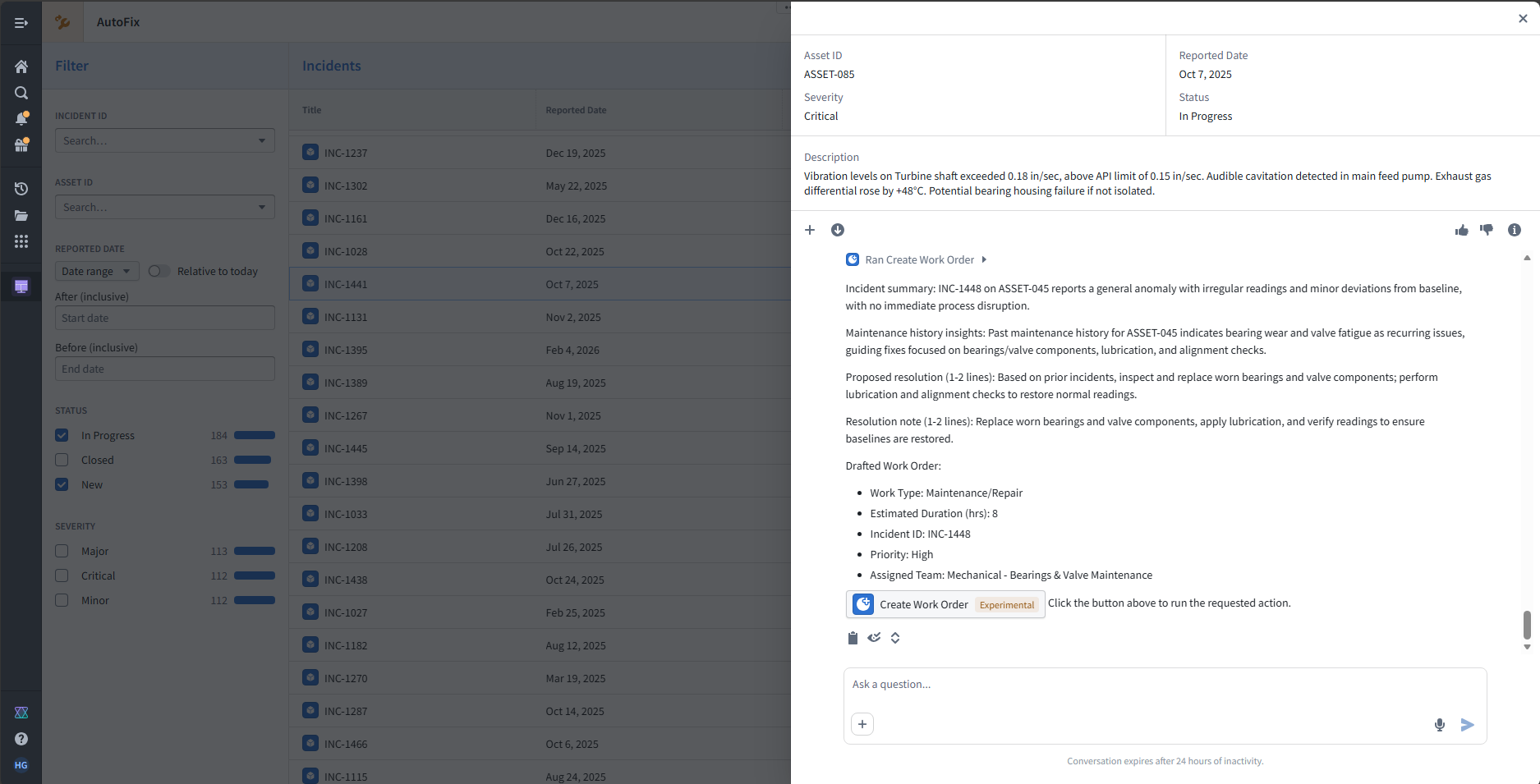
Now using Workshop, you can build an app that displays Incident list and detail view bound directly to Ontology objects. Whenever a row is clicked on table it open up a overlay, where the agent panel uses the selected Incident as context and summarizes and proposes a work order draft action and ask user for approval for better governance.
The user can additionally give feedback about the reply using the thumbs up/down button.
All of this is done within a single platform, with fewer separate services to integrate or writing any complex to code. This reduces end-to-end delivery time to a few weeks or less, with a more straightforward security and governance story.
Conclusion
Cloud primitives from Azure, AWS, and GCP are powerful and mature. They are often the right choice when teams require deep infrastructure control, want to experiment with highly customized architectures, or already have strong internal platforms and libraries. However, for many enterprises trying to operationalize GenAI on top of complex and sensitive data, the Integration Tax of assembling and maintaining a DIY stack is substantial.
Palantir Foundry tends to accelerate GenAI programs by: Providing a shared Ontology for live, structured business context, offering AIP Logic and Agent Studio to reduce glue code and orchestration complexity, embedding evaluation into the development lifecycle and enforcing security and governance consistently across data, models, and applications.
In practice, this often translates into faster Time-to-Market and faster Time-to-Value, with teams spending more effort on solving business problems and less on stitching together infrastructure.